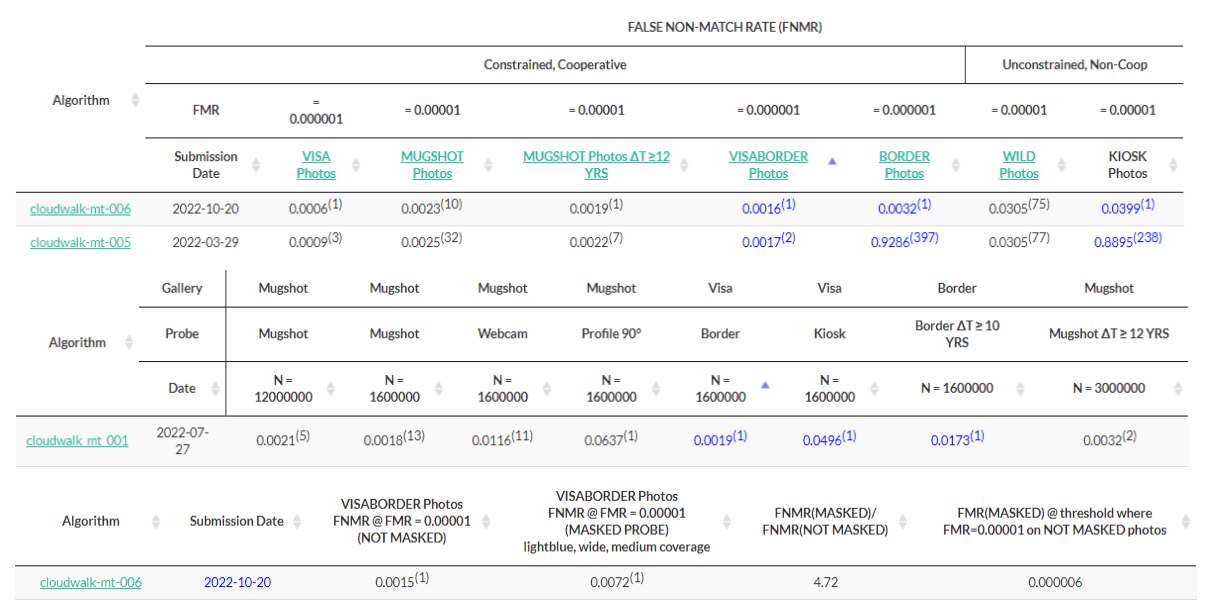
云從科技聯(lián)合上海交大發(fā)布AIGC跨模態(tài)數(shù)字人技術
近日,國際語音及信號處理領域頂級會議ICASSP2023在希臘成功舉辦。大會邀請了全球范圍內(nèi)各大研究機構、專家學者以及等谷歌、蘋果華為、Meta AI、等知名企業(yè)近4000人共襄盛會,探討技術、產(chǎn)業(yè)發(fā)展趨勢,交流最新成果。

云從科技與上海交通大學聯(lián)合研究團隊的《基于擴散模型的音頻驅(qū)動說話人生成》成功入選會議論文,并于大會進行現(xiàn)場宣講,獲得多方高度關注。
ICASSP(International Conference on Acoustics, Speech and Signal Processing)是語音、聲學領域的頂級國際會議之一, ICASSP學術會議上展示的研究成果,被認為代表著聲學、語音領域的前沿水平與未來發(fā)展方向。
本次入選論文,圍繞“基于音頻驅(qū)動的說話人視頻生成”這一視覺-音頻的跨模態(tài)任務,將語音與視覺技術結合,提出的方法能夠根據(jù)輸入的語音片段技術,生成自然的頭部動作,準確的唇部動作和高質(zhì)量的面部表情說話視頻。該項成果在多個數(shù)據(jù)集上,都取得了優(yōu)于過去研究的表現(xiàn)。
此外,在實戰(zhàn)場景中,隨著現(xiàn)實生活中對于數(shù)字人引用的愈來愈廣泛,實現(xiàn)用音頻驅(qū)動的生成與輸入音頻同步的說話人臉視頻的需求也越來越大。本項成果基于擴散模型的跨模態(tài)說話人生成技術,可以推廣到廣泛的應用場景,例如虛擬新聞廣播,虛擬演講和視頻會議等等。
論文地址:https://ieeexplore.ieee.org/document/10094937/
01
簡介
基于音頻驅(qū)動的說話人視頻生成任務(Audio-driven Talking face Video Generation):該任務是根據(jù)目標人物的一張照片和任意一段語音音頻,生成與音頻同步的目標人物說話的視頻。由于其生成的說話人更自然、準確的唇形運動和保真度更高的頭部姿態(tài)、面部表情,該任務廣泛應用于如數(shù)字人、虛擬視頻會議和人機交互等領域,作為視覺-音頻的跨模態(tài)任務,基于音頻驅(qū)動的說話人視頻生成也受到了越來越多的關注。
為了構建音頻信號到面部形變的映射,現(xiàn)有方法引入了中間人臉表征,包括2D關鍵點或者3D morphable face model (3DMM),盡管這些方法在音頻驅(qū)動的面部重演任務上取得了良好的視覺質(zhì)量,但由于中間人臉表征造成的信息損失,可能會導致原始音頻信號和學習到的人臉變形之間的語義不匹配。
此外基于GAN的方法訓練不穩(wěn)定,很容易陷入模型崩塌,往往它們只能生成具有固定分辨率的圖像。針對以上問題,AD-Nerf引入了神經(jīng)輻射場,將音頻信號直接輸入動態(tài)輻射場的隱式函數(shù),最后渲染得到逼真的合成視頻。但是基于神經(jīng)輻射場的方法計算量大導致訓練耗時長,算力要求高。
并且這些工作大多忽略了個性化的人臉屬性,無法準確的將音頻和唇部運動進行同步。因此本文的研究者們提出了本方法,通過借助去噪擴散模型來高效地優(yōu)化人臉各部分個性化屬性特征,進而合成高保真度的高清晰視頻。
02
方法
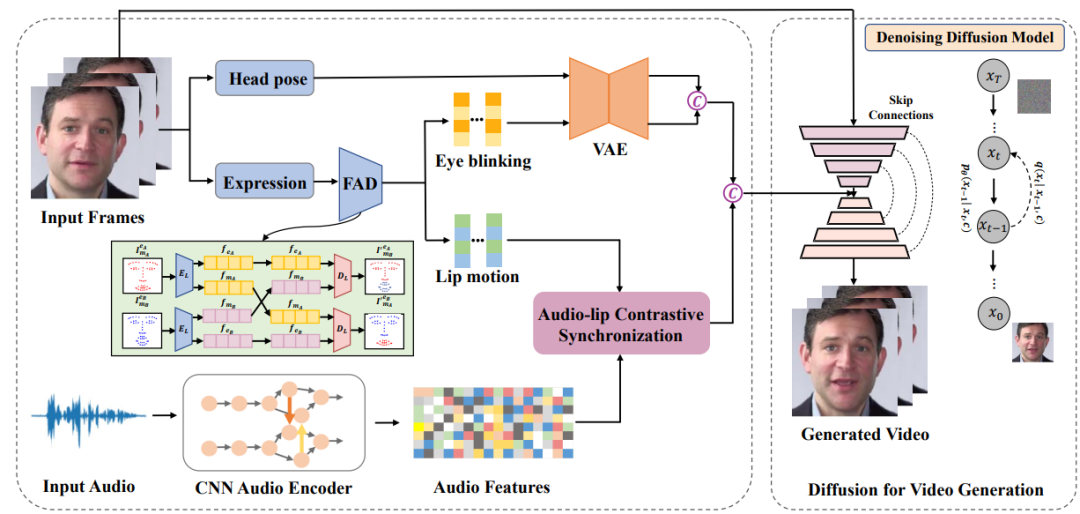
該方法首先基于一個關鍵的直覺:唇部運動與語音信號高度相關,而個性化信息,如頭部姿勢和眨眼,與音頻的關聯(lián)較弱且因人而異。受到最近擴散模型在高質(zhì)量的圖像以及視頻生成方面已經(jīng)取得了快速進展的啟發(fā),因此研究者們基于擴散模型重新構造音頻驅(qū)動面部重演的新框架,本方法來優(yōu)化說話人臉視頻的生成質(zhì)量和真實度。
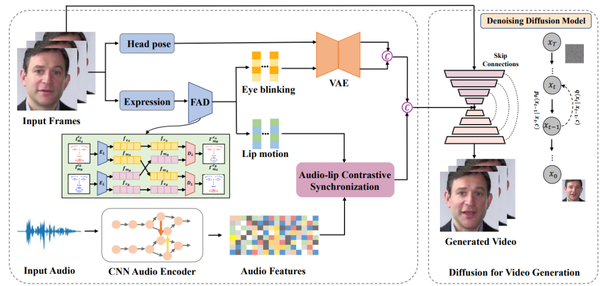
Difface一共包含四大部分:(1)人臉屬性解耦;(2)唇-音對比同步;(3)動態(tài)連續(xù)性屬性信息建模;(4)基于去噪擴散模型的說話人生成人臉屬性解耦部分中,研究者采用3DMM提取源身份圖像的頭部姿態(tài)和表情系數(shù),然后借鑒之前DFA-nerf的工作采用全連接的自編碼器從表情參數(shù)解耦得到唇部運動和眨眼動作信息。
唇-音對比同步模塊中,研究者通過引入自監(jiān)督跨模態(tài)對比學習策略來部署一個確定性模型來同步音頻和唇部運動的特征。
動態(tài)連續(xù)性屬性信息建模模塊中,由于頭部姿勢和眨眼等個性化人臉屬性是隨機的和具有一定概率性的,因此為了對人臉屬性的概率分布進行建模并生成長時間序列,研究者提出采用了基于transformer的變分自動編碼器(VAE)的概率模型,一是VAE可以用于平滑離散的屬性信息并映射為高斯分布,二是利用Transformer的注意力機制充分學習時間序列的幀間長時依賴性。
基于去噪擴散模型的說話人生成模塊中,研究者生成的個性化人臉屬性序列與同步的音頻嵌入相連接作為擴散模型的輸入條件。然后利用條件去噪擴散概率模型(DDPM)將這些驅(qū)動條件以及源人臉作為輸入,通過擴散生成的方式生成最終的高分辨率說話人視頻。這些個性化人臉屬性序列與同步的音頻嵌入用來豐富擴散模型,以保持生成圖像序列的一致性。
03
實驗結果
研究者們通過實驗驗證了本方法對于基于音頻驅(qū)動的說話人視頻生成任務的優(yōu)越性能。
? 定量比較實驗
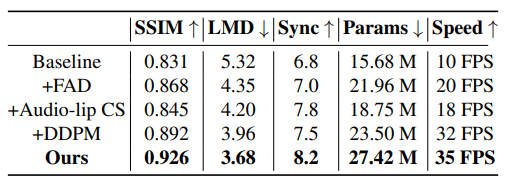
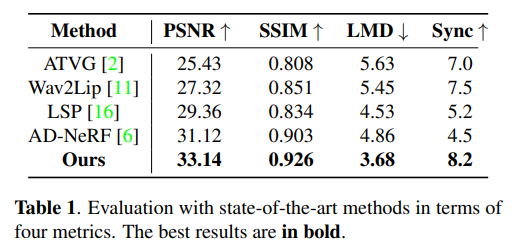
研究者將本方法與現(xiàn)有音頻驅(qū)動的人臉視頻生成方法通過定量化分析實驗進行比較,采用了峰值信噪比(PSNR), 結構相似度(SSIM),人臉關鍵點運動偏移(LMD),視聽同步置信度(Sync)等多個客觀的評估指標,具體信息如表1所示。
本文所提出的擴散生成框架在所有的性能指標上都優(yōu)于其他方法,其中PSNR和SSIM驗證了人臉屬性解耦方案能夠更好地捕捉說話人的頭部姿態(tài)、眨眼等個性化信息。而本方法的LMD分數(shù)意味著本方法的唇音一致性更強。此外,受益于輸入音頻和唇部運動的跨模態(tài)對比學習,本方法在Sync指標上大幅超越其他方法。
?定性比較實驗
研究者將本方法與現(xiàn)有音頻驅(qū)動的人臉視頻生成方法進行比較。通過個性化屬性的學習以及擴散模型的優(yōu)化,我們的方法生成具有個性化的頭部運動,更加逼真眨眼信息,唇-音同步性能更好的人臉視頻。
? 模型中每個模塊帶來的效益
為了突顯出模型中每個模塊的重要性,研究者們做了消融實驗,如表2所示,當添加DDPM模塊之后,在推理速度和視覺質(zhì)量方面相比于其他模塊的提升是最大的,其次,受益于解耦的人臉屬性信息以及VAE的屬性平滑以及動態(tài)連續(xù)性建模的作用,說話人人臉的自然度得到了提高。此外,唇音對比學習的模塊通過自監(jiān)督的方式顯著提高了唇部運動和與輸入音頻的同步質(zhì)量。
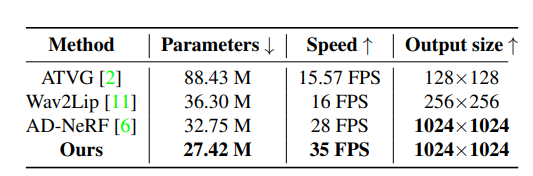
? 模型的效率
研究者們還展示了模型的可訓練參數(shù)量,推理速度以及輸出的分辨率大小,并和之前的SOTA模型進行了對比,由于使用去噪擴散概率模型,該模型利用變分方法而不是對抗性訓練,并且不需要部署多個鑒別器,因此極大緩解了訓練時模型容易陷入模型坍塌的問題,并且采用了較短的時間步長,推理速度大大提高,效率得到了提升。
04
結論
針對基于音頻驅(qū)動的高保真度說話人視頻生成這個任務,云從-上交的聯(lián)合研究團隊提出了,基于擴散框架的音頻驅(qū)動說話人視頻生成方法,只需要一幀或幾幀身份圖像以及輸入語音音頻,即合成一個高保真度的人臉視頻,實現(xiàn)了最先進的合成視頻視覺質(zhì)量。此外利用了跨模態(tài)唇音對比學習的方法,從而提升了唇部和音頻的一致性,在公開數(shù)據(jù)集上取得了SOTA表現(xiàn)。
您可能感興趣
-
 2023-06-27
2023-06-27云從科技與上海交通大學聯(lián)合研究團隊的《基于擴散模型的音頻驅(qū)動說話人生成》成功入選會議論文,并于大會進行現(xiàn)場宣講,獲得多方高度關注。
-
 2023-10-19
2023-10-19云從視覺基礎大模型表現(xiàn)出很強的泛化性能,大大降低了下游任務所需的數(shù)據(jù)依賴與開發(fā)成本,同時zero-shot大幅提高了訓練開發(fā)效率,使得廣泛應用和快速部署成為可能。
-